El formato PDF es un formato de archivo creado por Adobe y utilizado para presentar e intercambiar documentos de forma fiable, independiente del software, el hardware o el sistema operativo. Los archivos PDF pueden contener texto, imágenes, vínculos, botones, campos de formulario, audio y hasta vídeo. Cada documento PDF generado por una aplicación consta, normalmente, de una serie de hojas orientadas en sentido vertical que contiene una secuencia de párrafos de texto dispuestos en una única columna, los cuales pueden ser leídos con facilidad.
Eso es lo habitual. Pero a veces puede ocurrir que, al escanear un libro o exportar a PDF con LibreOffice, por ejemplo, se genere un documento compuesto por hojas en orientación horizontal (o apaisado) que contengan, cada una de ellas, dos páginas correlativas del libro. Lo cual resulta incómodo, pues la letra suele ser pequeña y nos obliga a ampliar la vista de página y a estar moviéndola continuamente para poder leer cada párrafo de texto. Voy a mostrar un ejemplo que me va a servir de hilo conductor para esta entrada.
Se trata de una hoja extraída de un documento que recopila algunos de los artículos publicados por Ramón Buenaventura en el dominical El Semanal 1, hace ya unos cuantos años. Como puede verse, dicha hoja contiene dos páginas (la 9 y 10), lo cual hace su lectura más laboriosa que si cada página estuviese en una hoja distinta. Por tanto, se hace necesario encontrar una utilidad capaz de reparar -de forma más o menos automática 2– dicha deficiencia en todas y cada una de las hojas afectadas.
Esa herramienta existe, y se llama Briss. Una aplicación de escritorio sumamente ligera que solo puede conseguirse descargándola desde la web, pues no se distribuye como paquete en ningún repositorio, por lo que tampoco requiere ser instalada en el sistema.
Primeros pasos
Al ser una aplicación escrita en Java, lo que sí es necesario instalar es un entorno de ejecución para Java, por ejemplo Openjdk:
$ sudo aptitude install openjdk-8-jre
A continuación descargamos la aplicación desde la página oficial del proyecto Briss, descomprimimos el fichero descargado, briss-0.9.tar.gz, en el directorio briss-0.9, accedemos a dicho directorio y le damos permiso de ejecución al fichero briss-0.9.jar (si es que no lo tiene ya):
$ wget https://downloads.sourceforge.net/project/briss/release%200.9/briss-0.9.tar.gz $ tar xzvf briss-0.9.tar.gz $ cd briss-0.9 ~/briss-0.9/$ chmod u+x briss-0.9.jar
Y lo ejecutamos desde un gestor de ficheros:
Abriendo Briss desde Thunar
O desde la misma línea de comandos (en segundo plano para poder seguir usando el terminal):
~/briss-0.9/$ java -jar briss-0.9.jar&
¿Cómo proceder?
Nada más abrirse la ventana de la aplicación, abriremos el fichero PDF que queramos reorganizar.
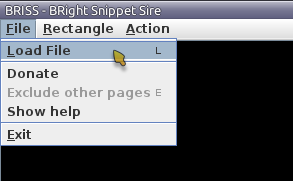
Abriendo un PDF
Y nos aparece una ventana como la siguiente:
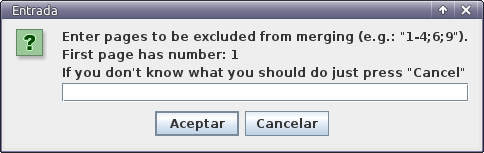
Ventana de filtro de páginas
Es posible que haya hojas en nuestro documento donde no sea necesario retocar nada porque no contienen páginas dobles. Por ejemplo, puede ser que la portada, la contraportada, o ciertas páginas de créditos, se hayan escaneado por separado, guardándose en hojas separadas del documento PDF. Por tanto, no hace falta dividirlas ni recortarlas, y quedarán excluidas de la acción de Briss. Supongamos que las tres primeras hojas y las dos últimas de nuestro documentos no contienen páginas dobles, y que hay 29 hojas en total. Por tanto, habrá que escribir en dicha ventana: 1-3; 28-29. Tras pulsar en Aceptar, nos saldrá algo como esto:
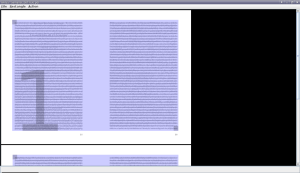
Área de trabajo de Briss (impares)
Y bajando la barra de desplazamiento, veremos esto otro:
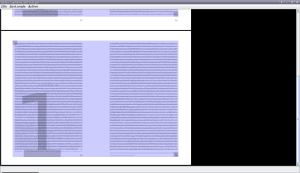
Área de trabajo de Briss (pares)
Vamos por partes.
En ambas imágenes vemos algo parecido a una página blanca que parece cubierta por una capa transparente rectangular de color azulado que lleva rotulada un número (el 1 en ambos casos).
La página de la imagen superior representa a todas a las hojas impares del documento, las cuales se muestran como si fuesen transparentes y estuviesen superpuestas una encima de otra; por eso podemos ver (o más bien, entrever) el texto de todas las páginas impares, desde la que está más al fondo, hasta la que está encima. Y, por analogía, la página de la imagen inferior representa exactamente lo mismo, pero referido a las páginas pares del documento PDF que hemos abierto.
¿Por qué se superponen las páginas pares por un lado y las impares por otro?. Pues porque es muy posible que los márgenes de las páginas impares sean distintos a los de las páginas pares. O sea, es habitual que la distancia de los cuerpos de texto a los bordes de las hojas de cualquier libro, revista o publicación, difieran en las páginas pares respecto de las impares. También es posible que las hojas impares contengan elementos que no existan en las pares (o viceversa). Por tanto, a la hora de realizar el recorte, habrá que seleccionar áreas diferentes en unas y otras.
Y esa capa azulada rectangular que cubre ambas páginas, representa al área que va a ser recortada y convertida en hojas del documento PDF que se generará al finalizar el proceso.
Esto significa que:
- como cada hoja del PDF original contiene dos páginas que se quieren separar y convertir en hojas independientes (y consecutivas) del PDF resultante, entonces, cada paquete de hojas representado en la interfaz de Briss (el paquete de las impares y las pares) deberá poseer dos capas transparentes: una para recortar las páginas de la izquierda y otra para recortar las de la derecha.

Selección de páginas por separado
-
el texto situado bajo el área cubierta por cada capa transparente será el que se vea en las hojas del PDF resultante. Eso significa que deberá cubrirse todo aquello que deseemos seguir viendo, por ejemplo los números de página. Y dejaremos fuera del área lo que no queremos que se siga viendo, por ejemplo el título del libro, o el nombre del autor, o una linea inferior, o cualquier otro elemento indeseado.
-
cada área que cubramos con las capas que hayamos creado será convertida en hojas independientes del PDF resultante, por tanto, es importante que dichas capas tengan las mismas dimensiones de ancho y alto. ¿Y cómo se consigue eso?. Muy fácil.
- redimensionamos la capa transparente que existe por defecto, tal como se muestra en la animación anterior, hasta que cubra solamente las páginas de la izquierda, dejando un margen razonable entre el texto y los límites de la capa. La seleccionamos colocando el ratón encima de dicha capa y, tras pulsar el botón derecho, haciendo clic en Select/Deselect rectangle del menú contextual. Saldrá algo así como esto:

Rectángulo izquierdo seleccionado
Podemos ver que aparecen las dimensiones en milímetros del ancho y alto de la capa. - ahora creamos con el ratón una nueva capa rectangular que abarque la zona derecha de la hoja, tal como se mostraba en la animación anterior; y la seleccionamos mediante el menú contextual, según acabo de explicar. Aparecerán las dimensiones de dicha capa, las cuales, salvo que tengamos un ojo y un pulso extraordinarios, serán distintas a las dimensiones del rectángulo de la izquierda.

Capas de selección en las hojas impares
En este ejemplo, la capa de la izquierda tiene unas dimensiones de 126⊗185 mm., y la que hemos creado en la derecha mide 123⊗186 mm.. - nos interesa que ambas capas transparentes, a izquierda y derecha de la hoja, tengan las misma dimensiones, para que todas las hojas del documento PDF resultante sean del mismo tamaño. Pero como sería complicado igualar las dimensiones a golpe de ratón, lo haremos de otra forma: manteniendo ambas capas seleccionadas, nos vamos al menú superior
Rectangle→Set size (selected)y nos sale esta ventana:
Igualando las dimensiones
Como se puede comprobar, Briss nos propone asignar a las dos capas seleccionadas unas dimensiones de 126⊗186 mm.. La elección de tales valores no es aleatoria, Briss elige la mayor de las anchuras (126) y alturas (186) de ambas capas. De esa forma, se igualan las dimensiones por exceso, para que los márgenes de las hojas resultantes tengan una mayor amplitud. - tras aceptar las dimensiones propuestas, veremos que las capas que recortan las hojas impares quedan redimensionadas y, lo más importante, con el mismo tamaño. Ahora habrá que repetir el mismo proceso con las hojas pares, las que se muestran debajo en la interfaz de Briss, de tal forma que sus capas izquierda y derecha tengan las mismas dimensiones que las de las hojas impares, o sea: 126⊗186 mm..

Capas de selección en las hojas impares
- redimensionamos la capa transparente que existe por defecto, tal como se muestra en la animación anterior, hasta que cubra solamente las páginas de la izquierda, dejando un margen razonable entre el texto y los límites de la capa. La seleccionamos colocando el ratón encima de dicha capa y, tras pulsar el botón derecho, haciendo clic en Select/Deselect rectangle del menú contextual. Saldrá algo así como esto:
❗ Hay que advertir que, tras uniformar el tamaño de todas las capas, conviene ajustar la posición de cada una para que el cuerpo de texto que hay debajo quede perfectamente centrado dentro del rectángulo. Esta operación se debe realizar colocando el ratón dentro de la capa y moviéndolo con el botón izquierdo pulsado.
Comprobar y generar el resultado
Ya hemos diseñado los recortes que efectuaremos en todas las hojas del documento. Ahora solo queda comprobar como queda en una vista previa, antes de ejecutar la herramienta de recorte. Para ello nos dirigimos al menú Action → Preview para abrir el documento resultante en un visor PDF. Si se han hecho las cosas bien, verás que el dicho documento contiene en cada hoja una página del documento original, y tiene unos márgenes verticales y horizontales lo bastante amplios como para posibilitar su lectura. Veamos como quedaría la hoja de ejemplo mostrada al principio, después de ser modificada:
Si el resultado nos parece satisfactorio terminaremos ejecutando la herramienta de recorte a través de Action → Crop PDF, y asignándole un nombre al nuevo fichero PDF que se va a generar.
Acotaciones
- el número que aparece impreso en cada capa rectangular expresa el orden en que será colocada la hoja extraída de dicha capa una vez que se haya realizado el recorte. De ese modo, por cada hoja del documento original, la hoja extraída de la capa izquierda (que muestra un 1) estará situada antes que la hoja de la capa derecha (que muestra un 2) en el documento resultante. Esto es aplicable al paquete de las impares y las pares.
- Si antes de comenzar el procedimiento se excluyeron hojas que no necesitaban ser recortadas, dichas hojas seguirán estando en los mismos lugares y en el mismo orden dentro del PDF resultante.
Conclusión
Leer un documento en PDF mal construido o estructurado es un fastidio importante. Y no todo el mundo sabe generarlo correctamente, bien por ignorancia o, peor aún, por vagancia.
Esta herramienta permite, como hemos visto, solucionar fácilmente el problema de los PDF generados a partir de textos escaneados a doble página. Aunque es incapaz de arreglar aquellos PDF‘s defectuosos que contienen, por ejemplo, páginas escaneadas con diferente niveles de aumento (zoom). En tales casos, el documento PDF generado con Briss contendrá hojas en las que el texto ocupará casi todo el espacio, y otras en las que el texto aparecerá reducido y con unos márgenes enormes.
Tampoco se puede hacer nada con Briss cuando el texto escaneado aparece borroso (movido), o muy oscuro, o muy claro. En esos casos, lo mejor es buscar ese libro o revista en otra fuente. O comprárselo. 🙄
- Artículos que, en muchos aspectos, no han perdido vigencia a pesar del tiempo transcurrido; por lo cual recomendaría encarecidamente su lectura. Además, hay varios de ellos dedicados a nuestro sistema GNU/Linux. ↩
- Podría hacerse de forma manual extrayendo en ficheros de imagen todas las hojas del documento, recortando por la mitad cada imagen para que cada página se guardase en un fichero distinto y volviendo a recomponer el documento PDF con los ficheros de imagen así obtenidos. Pero convendrán conmigo en que eso es un trabajo de chinos. ↩




Pingback: La navaja suiza del PDF | #LINux #SOftwareLIbre #TIC